
 Peter Alcock
c30e6b515b
Update INSTALL
Peter Alcock
c30e6b515b
Update INSTALL
|
2 gadi atpakaļ | |
|---|---|---|
| engine | 2 gadi atpakaļ | |
| engine-scaler | 2 gadi atpakaļ | |
| group_vars | 2 gadi atpakaļ | |
| roles | 2 gadi atpakaļ | |
| .gitignore | 2 gadi atpakaļ | |
| INSTALL | 2 gadi atpakaļ | |
| LICENSE | 2 gadi atpakaļ | |
| README.md | 2 gadi atpakaļ | |
| Vagrantfile | 2 gadi atpakaļ | |
| contactrocket.mp4 | 2 gadi atpakaļ | |
| emails.jpg | 2 gadi atpakaļ | |
| engine.jpg | 2 gadi atpakaļ | |
| logo.png | 2 gadi atpakaļ | |
| screenshot.jpg | 2 gadi atpakaļ |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
README.md
![]()
This is a project I obsessed over for way too long several years ago, I lost countless hours of sleep working on it and ultimately failed to launch a SaaS product (marketing is expensive). It has sat uncelebrated on my external hard-drive "mountain" for years, and since I am on the hunt for a new RoR-heavy technical role, figured I may as well just give it away and sacrifice my monetization pipedream to make an open-source contribution as an expression of my gratitude for Ruby on Rails, Sidekiq (Mike Perham, you're the fucking man.) GitHub, Amazon Web Services, and the internet. Thanks to these aformentioned corporate and human entities, my life-long love for software has been all the more enjoyable. Gladiators, I salute you.
Getting Started
I can't believe how long I've been using Docker. This whole thing is containerized into a few core services: CRM, Dashboard, and the Engine. If you know Docker and Rails and AWS, you should be fine. If you don't, watch this cute explainer video I made instead... ![]()
Infrastructure / Deployment
I set this up to easily be deployed on Elastic Beanstalk and created a series of ansible scripts to do all the configuration for you. But if you wanna kick some real ass, there are a few tweaks to make in order to give my spider engines unlimited scaling power on AWS (albeit this will be very expensive, so it ain't the default). PostgreSQL stores the records created from crawls, Redis is used in combination with a bloom filter and hiredis client (for performance) to keep track of all the pending crawl jobs and to track previously crawled URLs. ElasticSearch is used to make all of the returned results searchable, with each added record being asynchroniously indexed by the background workers to prevent bottlenecks. You will wanna tune the Redis configuration to use the LRU cache policy (least recently used) for when it needs to choose was to abandon. Using LRU will result in punting problematic URLs first when memory starts to bloat on the EC2 instance from crawling too fast and running too hard. Amazon's ElastiCache can be used for background job data store. For finer control you will want to run your own Redis cluster, and you can use Amazon's Elasticsearch service if you don't know how to run your own ES cluster. (No, I will not go into how to do this right now. Hire me to do it for you.)
Web Dashboard / Front-End
I created the dashboard using websockets and AJAX to deliver live visual indicators of your crawlers progress because it's much more exciting to watch than having to refresh the page everytime a user wants to "check their score". A thousand man hours went into this simple improvement to the UX/UI, so be grateful.
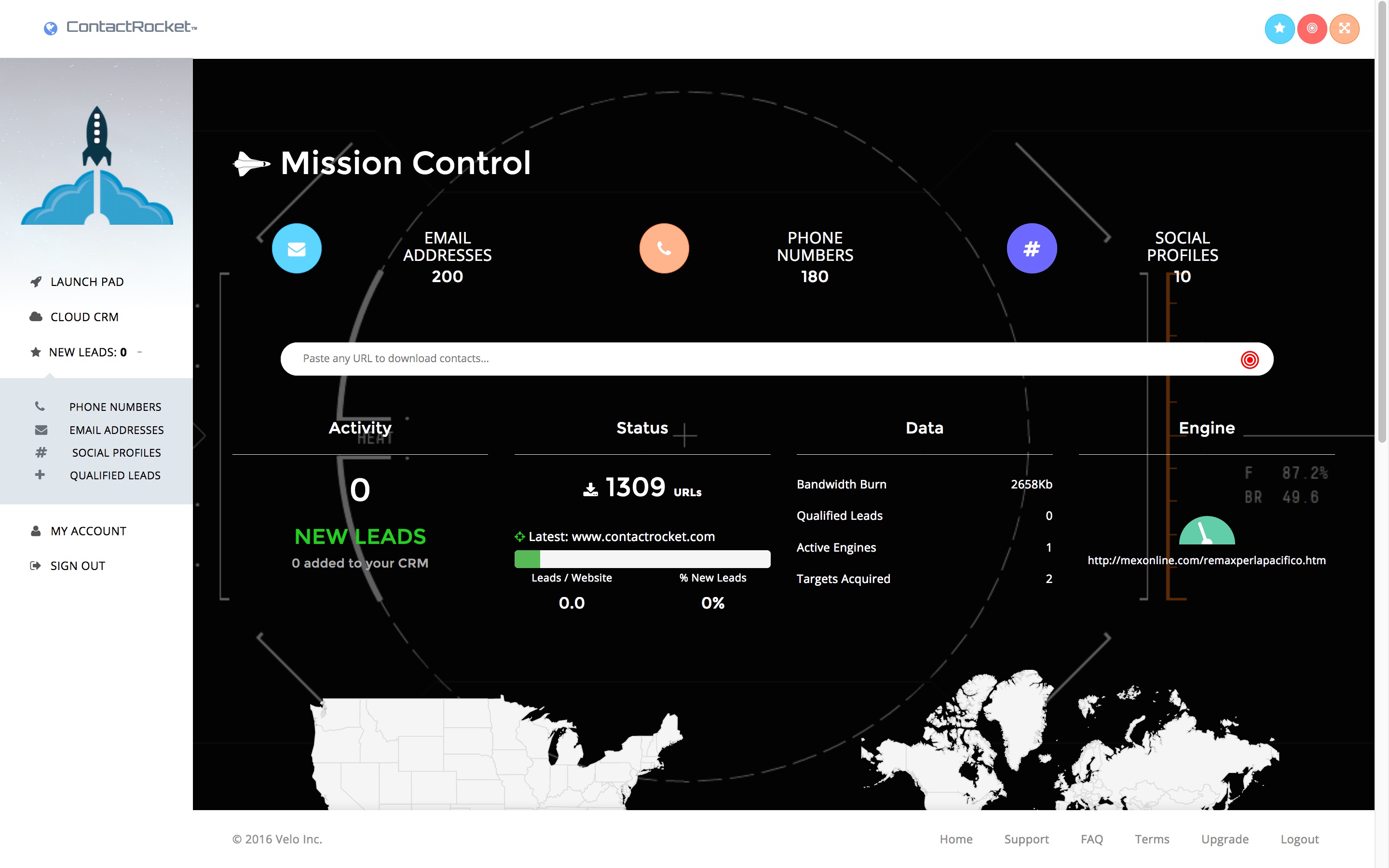
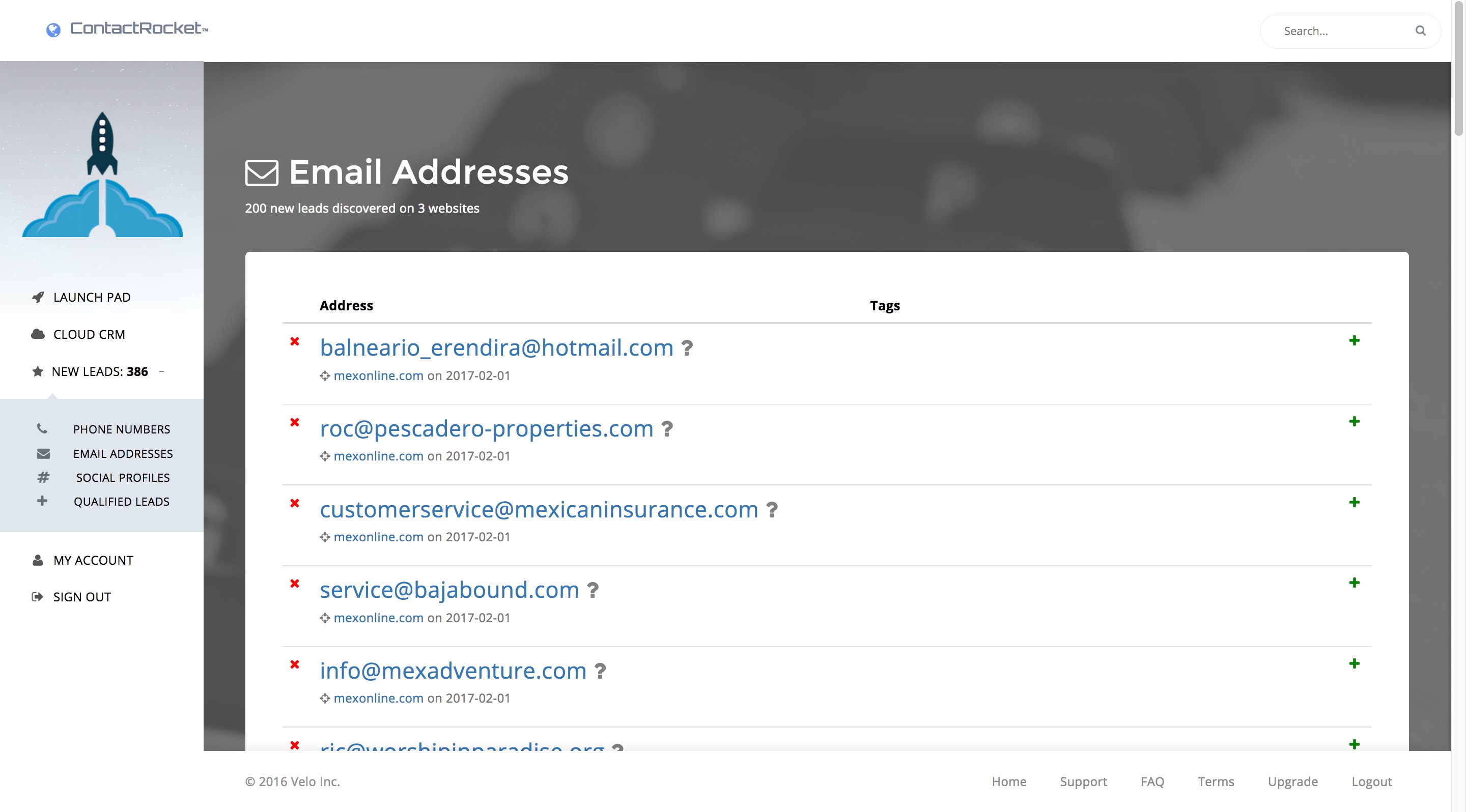
Crawler Engines / Back-End

Background processing engines are broken into separate parts for separate purposes. Social Media crawling is network intensive, cached page crawling is as well, returned data is very write-heavy on the I/O for RDS instances (or however you decide to host your SQL store), both of which Amazon charges a pound of flesh to consume (look into "IOPS Provisioning" if you don't believe my warning). I may recommend running the engine workers on Linode or DO, albeit at a significant latency cost between the back-end and the front-end. But hey, it's your money.
Scaling Up
If you want to crawl millions of websites in an evening with this you will need to use the deployment scripts I've included for Amazon Web Services' Auto-Scaling EC2 clusters. This will cost you a pretty penny, but I've optimized these scripts to dynamically configure themselves to whatever size EC2 you choose to use by making the deployment script aware of the number of cores and available memory on their server and adjusting the multi-threading configuration accordingly. Make sure you database connections match your worker threads counts. 10-25 is typically the appropriate range. You're welcome.
Testing
I have written tests for every function of the engine, and then some. It's all done in RSpec with Capyabara-Webkit handling headless browser simulations for testing the web dashboard, which can be a dependency nightmare, so use my https://github.com/peteralcock/rubylab repo to jumpstart your success.