
README.md 2.6 KB
CONTACTROCKET
Spent a summer building this marketing SaaS using Ruby on Rails and Sidekiq background processing to support an army of ruby web crawlers tuned specifically for rapid lead-generation automation and contact data enrichment for sales prospecting. Bulk collect emails, phone numbers, social media, and then link them by textual index proximity weighted confidence scores. I decided to give it away for free instead of monetizing it. Then I realized what a mistake that was as I watched competing products later grow to become $100 million dollar companies. But it's whatever. Coffee is for closers.

Deployment
PostgreSQL stores the records created from crawls, Redis is used in combination with a bloom filter and hiredis client (for performance) to keep track of all the pending crawl jobs and to track previously crawled URLs. ElasticSearch is used to make all of the returned results searchable, with each added record being asynchroniously indexed by the background workers to prevent bottlenecks. You will want to tune the Redis configuration to use the LRU cache policy (least recently used) for when it needs to choose what links to ultimately abandon after multiple retries. Using LRU will result in punting problematic URLs first when memory starts to bloat on the EC2 instance.
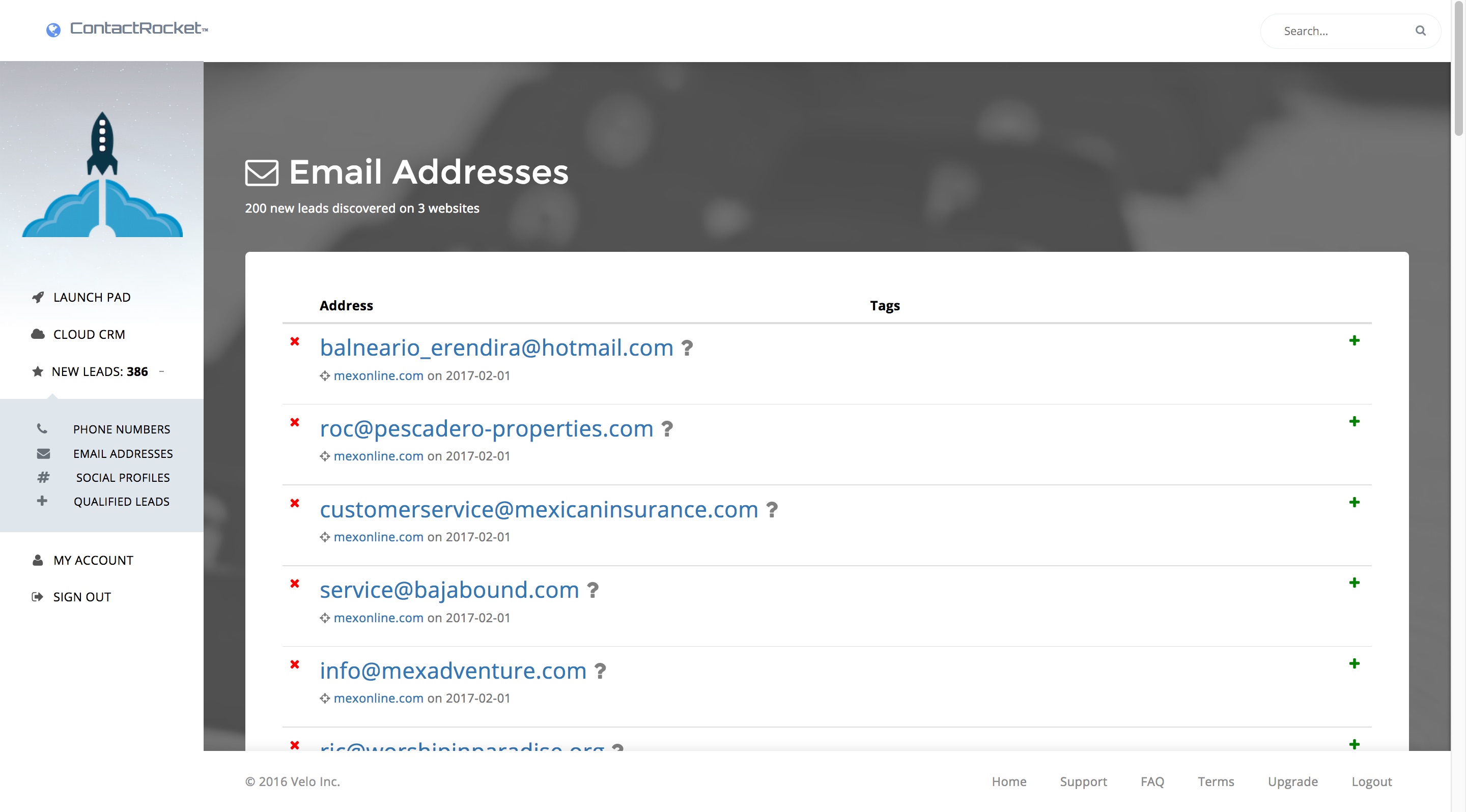
Dashboard
The dashboard uses websockets and AJAX to deliver live visual indicators of your crawlers progress.
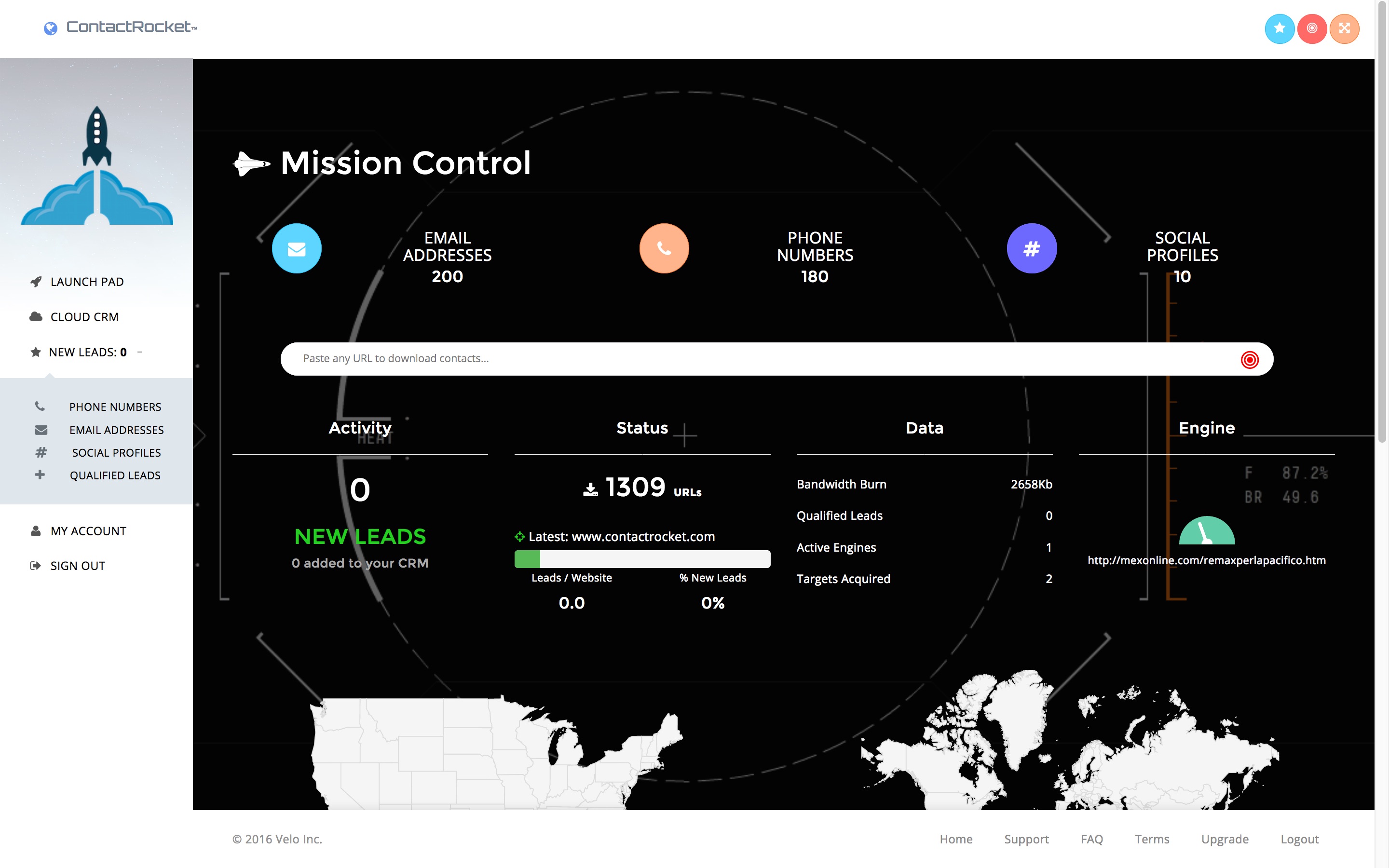
Engine

Background processing engines are broken into separate parts for separate purposes. Social Media crawling is network intensive, cached page crawling is as well, returned data is very write-heavy on the I/O for RDS instances.
Scaling
If you want to crawl millions of websites in an evening with this you will need to use the deployment scripts I've included for Amazon Web Services' Auto-Scaling EC2 clusters. This will cost you a pretty penny, but I've optimized these scripts to dynamically configure themselves to whatever size EC2 you choose to use by making the deployment script aware of the number of cores and available memory on their server and adjusting the multi-threading configuration accordingly. Make sure you database connections match your worker threads counts. 10-25 is typically the appropriate range.
Testing
Capyabara's headless browser simulations are dependency nightmares. Use my https://github.com/peteralcock/rubylab repo to jump start TDD.